
Change Data Capture - Capture Data In Motion in your microservices
Change Data Capture - How to track Data in Motion by using microservice patterns such as Outbox, Saga, Strangler Fit Pattern

Developer who sees beyond the hype
Data is the new oil. It keeps on coming and difficult to manage where there are multiple sources. Also, the database is not just a table as it used to be. Their are a multiple of formats and use-cases for data. It could be traditional Relational Databases, it could be data warehouse for analytical process, it could be a short-lived cache for performance improvement, it could a search index for optimising Database query reads, it could be a event notification that needs to be sent out to customers and the list goes on.
Basically, all these are changes or deltas that need to be sent from source to destination. That is where Change Data Capture (CDC) comes in.
What and Why of CDC
What is CDC?
CDC is a paradigm to track changes in database (create, update, delete operations) and send those data to destination so that data is in-sync with real values
Why CDC?
The concept of data is not confined to a single table or a schema. It evolves, it moves around for various applications. Also the format of the said data is non-uniform.
Traditional Databases are good for Client-Server applications where APIs expose CRUD operations for the database. Data is usually noramalized form in various tables. For analytical, OLAP databases are good which requires to be in denormalized forms. Since there is a difference/delta in the schema; we need a CDC or a ETL pipeline that is able to convert the data into the appropriate forms. Another example is for Data Another example would be sending data to cache so that cache can be invalidated for stale values and inserted for updated values. RDBMS work with tables while Cache is a Key-Value Store. Again, we need a way to translate RDBMS's table-type data to Cache's KV store. (Blog on how to do this)
Pull vs Push Based
Push
Here the source database does most of the work. It implements the capture changes, transformation, send update to target services. Disadvantage is that it does not consider the fallacies of distributed computing such as Network is not unreliable, hence the destination will have inconsistent state.
Pull
Here there the target services takes the job of pulling from the data source. Drawback is that it is a new paradigm with a lot of plumbing required to make this work.
CDC Implementation
Timestamp-based
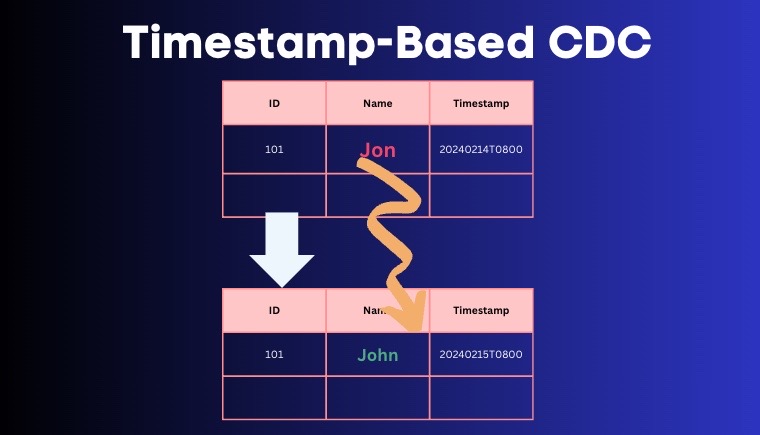
LAST_UPDATED_BY column are used by downstream services to get the latest information. It is dead-simple. but there are a couple of major drawbacks:
Soft deletes (Deletes which are available as row but not persisted to disk) is possibe, but not
DELETEoperations that are persisted.Target systems scanning the database is not a free-lunch process. It adds overhead to source database.
Data might be outdated as in-progress transaction can lead to data inconsistencies in target systems.
Trigger-based
Most Relational Databases have TRIGGER functions. These functions (aka Stored Procedures) that can be initiated to a database event (INSERT , UPDATE etc) Issue with trigger-based is the overhead on database as every write to database requires 2x resource (1 for update table, other for trigger actions)
Log based
Debezium Used this approach
A pull-based mechanism that reads the logs emitted by DB. This could be Write-Ahead-Logs that are saved in Databases
BinLog for MySQL
Replication Slots for Postgres
REDO Log Oracle equivalent
Libraries
Kafka connect
It is a middle-ware to connect Kafka with external systems such as Databases, Data Warehouse, Caches (K-V stores), file systems (S3 etc), and search indexes.
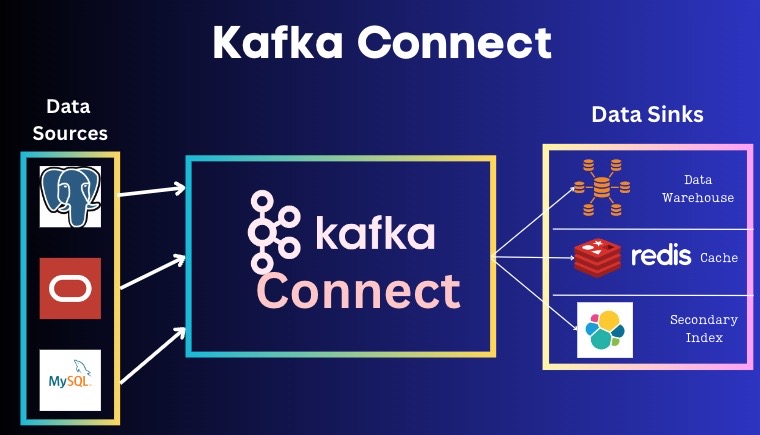
Kafka Connect can take data from source connector as an ingest, and deliver this data to sink connector such as HDFS, Indexes such as Elasticsearch etc Source and Sink Connectors are configured so that the data ingestion and egress is possible based on those configuration.
Debezium
OSS CDC platform with a lot of connectors for various different type of data sources.
Debezium Features
Reads Transaction Logs on database (WAL; BinLog MySQL, REDO Log Oracle & Replication Slots Postgres)
Outbox pattern support (Explain Outbox pattern)
Web based UI
Purely OSS
Large production deployments
Debezium Deployment Options
Kafka Connect
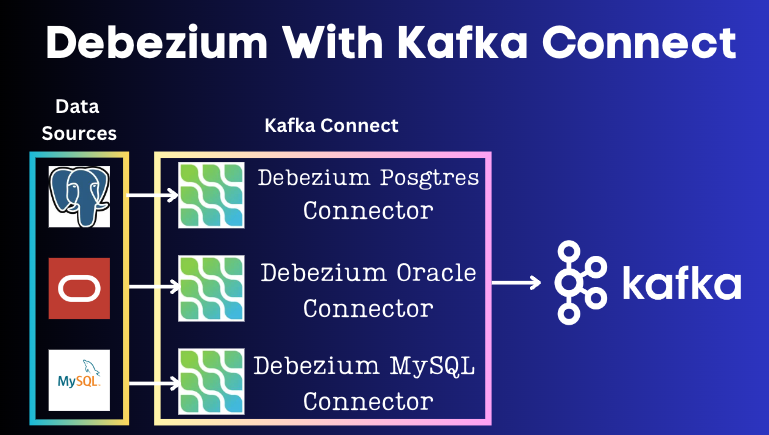
DS -> Kafka Connect (Debezium DB-specific connector) -> Kafka
Debezium Embedded Engine (Java only)
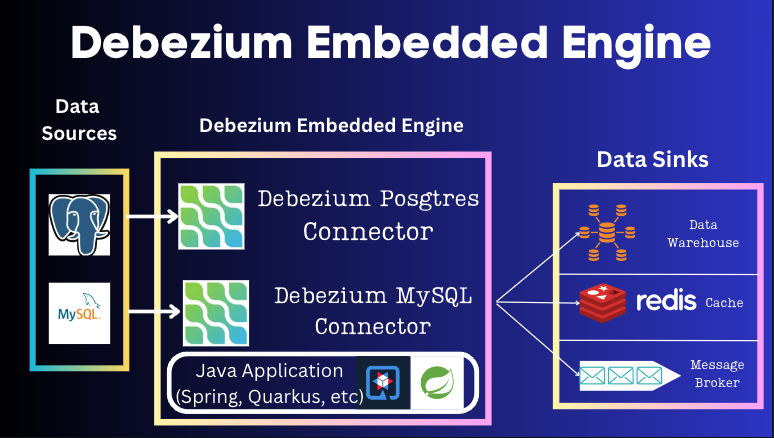
DS -> Debezium Embedded Engine (Spring, Quarkus) (Debezium DB-specific connector) -> WHatever you want
Debezium Server
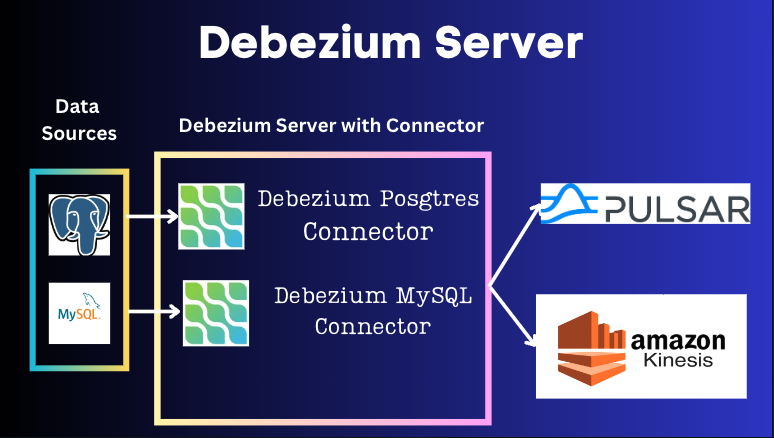
DS -> Embedded Engine Source Connectors (Debezium Server) -> Kinesis, Pulsar, Google Pub/Sub
CDC Patterns
Transactional Outbox Pattern
Problem Statement
Consider you have a main microservice (Insurance Claim μs) that has a couple of downstream services (Insurance Settlement μs & Credit Score μs)which are dependant on the aforementioned Insurance Claim μs. The downstream APIs consume the upstream Insurance Claim μs via a message broker (Could be Kafka, Pulsar, RabbitMQ etc). In Distributed Systems, we have 8 fallacies of Distributed Computing (Read wiki); first one is api in this scenario i.e. Network is Reliable. Consider the Credit Score μs Kafka Topic/whatever message broker you are using is down for some reason! In such a scenario, we don't want 2 out of 3 μs to be in consistent while the Credit Score μs to be inconsistent. Hence, Outbox Pattern to rescue us in this conundrum. We need to send the events reliably! Reliably means that it should be consistent with the Event that is being produced by the upstream Insurance Claim μs. And it should handle system crashes such as Server, Message Broker, database, N/W packet loss etc. Basically, you got to assume Murphy's Law!

One question for those aware of 2-Phase commit(aka XA transactions)would ask as it is also concerned handling consistent and atomic writes across different databases. The issue with 2PC is that it requires similar database and message broker setup and to be able to support 2PC out-of-the-box. Many message brokers and NoSQL cannot support 2PC, hence we are going up with this pattern.
If at-least-once semantics are present it will lead to dual-writes!
Solution
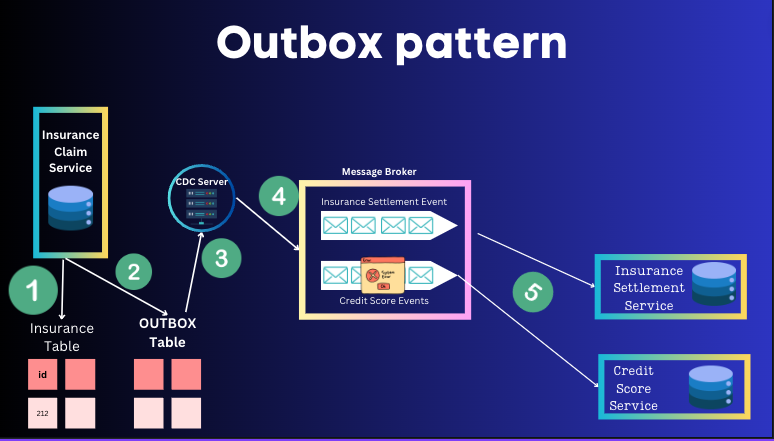
Since we do not have possibility of using 2PC (XA transaction), we need to find an alternate path of making the event messages to be sent reliably and persisted in the downstream services.
The basic fundamental of this is that we do not directly add the events to the Event Bus/Message Broker. We add an Outbox Table which stores the messages to be sent. The table would look something like this:
| SpanId | AggregateType | PrimaryId | EventType | Payload |
|---|---|---|---|---|
| dd12 | InsuranceClaim | 212 | InsuranceClaimCreated | {id:212,...} |
The Change Data Capture server acts like a message relay that read this Outbox table and sends to Message broker which then passes on the event to downstream.
(Postgres does not need as they have pg_logical_emit_message())
The below diagram shows the steps
Add to Insurance Table
Insert to Outbox Table with the IDs, payload, Event Name (and other columns)
CDC Server (like Debezium) reads the Outbox table
CDC Server send this Event to Message Broker (like Kafka)
Sends data to downstream services and their associated Databases
This ensures:
Event messages are sent if and only if the data transaction is completed in source microservice.
Message Ordering is maintained at the Message broker as a single topic partition failure does not create a delta of inconsistent data.
Drawbacks of this pattern:
- Additional resource and tables required.
Strangler Fit Pattern
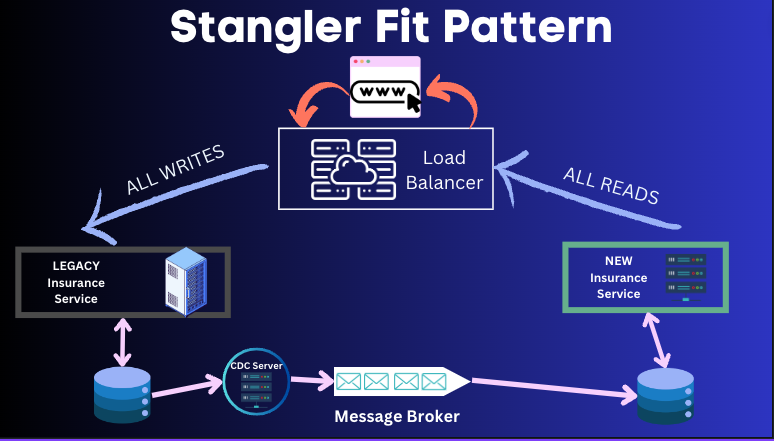
It is a pattern to allow for incremental migration from a legacy service to a greenfield new microservice. Here CDC is a very useful pattern to incrementally migrate the services from legacy to new.
In this pattern, the first step is to setup the new service in such a way that the new services's Database is able to read from the old database. CDC along with message broker can allow the writes to go from the legacy database to the new service.
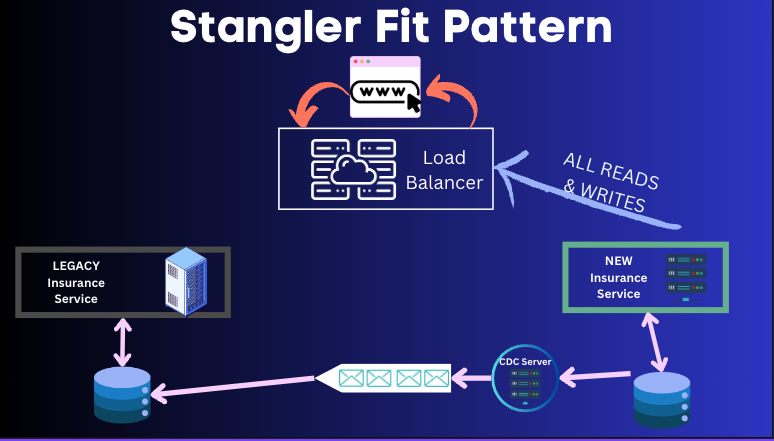
Here the user will write to legacy but will be reading from the new service. This is achieved by load balancing the requests so that the reverse proxy routes all writes to the legacy and the reads come from new service. Once the new service is at feature-parity with the legacy; then the reverse proxy can route the writes also to the new service. As the bonus step, reverse-CDC can also occur to insert the data from the new service to the legacy database via the reverse CDC Message broker setup.
SAGA Pattern
Solve for Long Running Service Transactions
Sometime the microservices are not so simple to execute. They might be some transactions that take a lot of time and a simple Request/Response API is not enough to bring Database consistency.
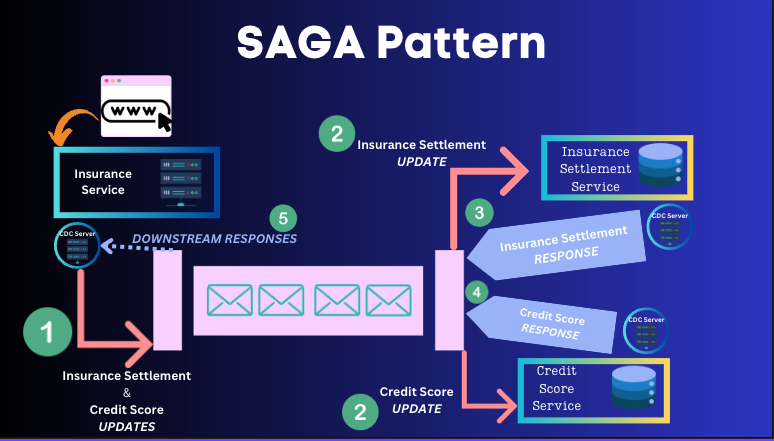
Here the upstream Insurance Claim μs is dependent on Insurance Settlement and Credit Score service which is a slow process which can take more than n2 business working days to fulfil. Here SAGA pattern comes into the picture. Unlike Outbox Pattern where the upstream changes needed to be propagated to downstream reliably; here the downstream needs to propagate its state to the upstream service Insurance Settlement μs & Credit Score μs.
The pattern works as follows:
Insurance Claim μs sends the updates to the message broker
Message broker fans-out the event to downstream services Insurance Settlement μs & Credit Score μs
and 4. Insurance Settlement μs & Credit Score μs propagate their results to the message broker via a CDC server.
Insurance Claim μs receives both responses and makes a decision.
Drawbacks:
- Without Observability, it is difficult to debug/trace the transactions across service, database and message broker.
Resources
Everything Gunnar Murling




